Dissecting Alzheimer's disease heterogeneity by cross-trait polygenic prediction
Mapping the genetic basis of inter-individual heterogeneity in multifactorial diseases opens the door to mechanistic insights and opportunities for targeted intervention. In Alzheimer's disease (AD), clinical and pathological heterogeneity is well recognized, but genetic dissection is limited by a lack of well-powered cohorts with deep phenotypic characterization.
In this project, led by Bill Li, we propose using cross-trait polygenic scores to dissect the genetic basis of phenotypic heterogeneity in Alzheimer’s disease. Please see Bill’s LinkedIn post and our manuscript for more details.
This project builds on our previous work developing sparse polygenic score models across UK Biobank traits. In this manuscript, we use a subset of the models from our 2022 PLOS Genetics paper, where we reported 813 significant sparse PGS models.
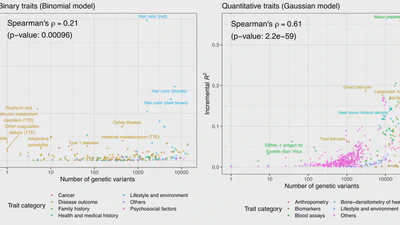
Significant Sparse Polygenic Risk Scores across 813 traits in UK Biobank
We performed a systematic assessment of the predictive performance of PRS models across >1,500 traits in UK Biobank and report 813 PRS models with significant predictive …