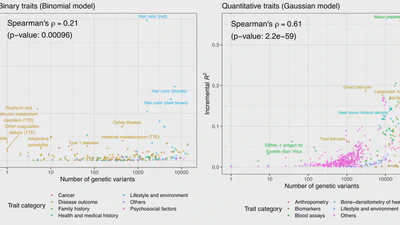
Significant Sparse Polygenic Risk Scores across 813 traits in UK Biobank
We performed a systematic assessment of the predictive performance of PRS models across >1,500 traits in UK Biobank and report 813 PRS models with significant predictive …
Assistant Professor
Mapping the biological basis of heterogeneity in disease.
Yosuke Tanigawa is an Assistant Professor in the Department of Bioengineering at UCLA. He leads the Tanigawa Lab, which studies why individuals with the same diagnosis differ in disease onset, progression, and treatment response.
The lab develops statistical and computational methods for large-scale genetic, genomic, and phenotypic data. The work spans disease heterogeneity dissection, ancestry-aware polygenic prediction, and therapeutic target discovery from human genetics.
Before joining UCLA in July 2025, Yosuke trained at the MIT Computational Biology Lab with Manolis Kellis. He received his PhD in Biomedical Informatics at Stanford University, where he worked with Manuel Rivas and Gill Bejerano.
The lab values scientific rigor, open science, and clear communication. We aim to make complex human genetics accessible without losing scientific precision.
We performed a systematic assessment of the predictive performance of PRS models across >1,500 traits in UK Biobank and report 813 PRS models with significant predictive …

We analyzed the genetic basis of 35 blood and urine biomarkers in UK Biobank. We revealed that genetic effects on biomarkers inform the genetic basis of disease.
We identified an allelic series of rare protein-altering variants in ANGPTL7 that lower intraocular pressure and protect against glaucoma, highlighting ANGPTL7 as a therapeutic …

We developed DeGAs to decompose shared genetic associations across 2,138 UK Biobank phenotypes and identify their underlying pleiotropic structure.